Your Own Semantic Space — a Nemotron Embedding NIM on a DGX Spark
The embedding endpoint that every downstream RAG, wiki, and agent piece will reuse — a 2048-dim Nemotron Retriever NIM running locally on GB10, ready 52 seconds after docker run and holding 28 docs/s under batched load.
An embedding model doesn’t answer questions. It turns text into geometry. Every sentence you hand it becomes a point in a fixed-dimensional space, and every downstream retrieval decision — is this passage relevant, are these two pages duplicates, does this agent trajectory resemble a prior one — collapses into a distance calculation between points. Article #3 put an inference endpoint on the Spark. This article puts the semantic space on it. From here on, everything the three arcs need — corpus vectors, wiki dedup, trajectory recall — is a curl to localhost.
The short version: NVIDIA’s Nemotron Retriever 1B embedding NIM pulls cleanly onto the Spark from a multi-arch manifest, loads in 52 seconds cold, emits 2048-dimensional vectors with Matryoshka truncation down to 384, and plateaus at about 28 documents per second under batched load. The longer version is more interesting, because the first candidate I checked is deprecated in 27 days, and picking the right NIM the first time is most of the article. That naming recon, the arm64 manifest check that unblocked the install, and the throughput shape under batching are the things a reader would miss if they only skimmed the Deploy tab.
Why embeddings matter more than the endpoint
Embeddings are the place where the Spark’s economics flip hardest. A cloud embedding API charges you per call — and retrieval systems are chatty, because every query embeds once and every corpus document embeds once. A personal-scale corpus of ten thousand notes turns into ten thousand outbound calls at ingest, plus one more per query, forever. The per-call price is small; the rate limit is not, and the privacy implications of mailing your entire notes archive to a third-party API are the reason most individuals don’t stand up a real RAG system at all.
Put the same endpoint on your desk and both costs go to zero. The embed call never leaves the box, never costs a dollar, never hits a rate limit. The corpus stays where it was. The box where the bytes already live is the box where the vectors get computed, and the Spark’s 128 GB of unified memory swallows an 8B-parameter LLM and a 1B-parameter embedder simultaneously with headroom for the reranker that article #7 will add. Small-model-cheap and big-model-cheap are both rentable; both-at-once-locally is what turns a RAG idea into something an individual actually finishes.
Where this sits in the stack
NIM is still the packaging layer, but the engine inside the embed container is different from the LLM NIM’s vLLM. Nemotron Retriever embeds ship on Triton 2.61 — the metrics, the HTTP server, the GRPC fan-out all come from Triton rather than a chat-oriented engine. The model itself is a transformer encoder fine-tuned bi-encoder-style for retrieval: query and passage go through the same weights independently, contrastive training pulls relevant query-passage pairs close in the output space and pushes irrelevant ones apart. Matryoshka training makes the output dimension adjustable at read time — the first 384 components of the full 2048-d vector are themselves a valid, shorter embedding. That’s the knob you tune for pgvector index size later.
The journey
Recon — and a deprecation gotcha
The obvious search on build.nvidia.com/spark/ returns nothing tagged “embedding.” The Spark playbook index (NIM-on-Spark, vLLM, SGLang, TRT-LLM, NVFP4, llama.cpp, LM Studio, Nemotron-3-Nano, multi-modal, speculative decoding) is LLM-inference-centric; the RAG AI Workbench playbook gestures at embeddings without pinning a model, and Text-to-Knowledge-Graph explicitly lists embeddings under “future enhancements.” So the Spark catalog doesn’t have a dedicated embedding playbook yet. That’s useful information: no -dgx-spark suffix exists for an embedder, which means the same image has to work on both Spark and regular datacenter GPUs.
The /search?q=embed query in the model catalog returns six reasonable candidates. The one my prior handoff flagged — llama-3.2-nv-embedqa-1b-v2 — looks like the obvious pick until you open the deploy page and see the warning strip:
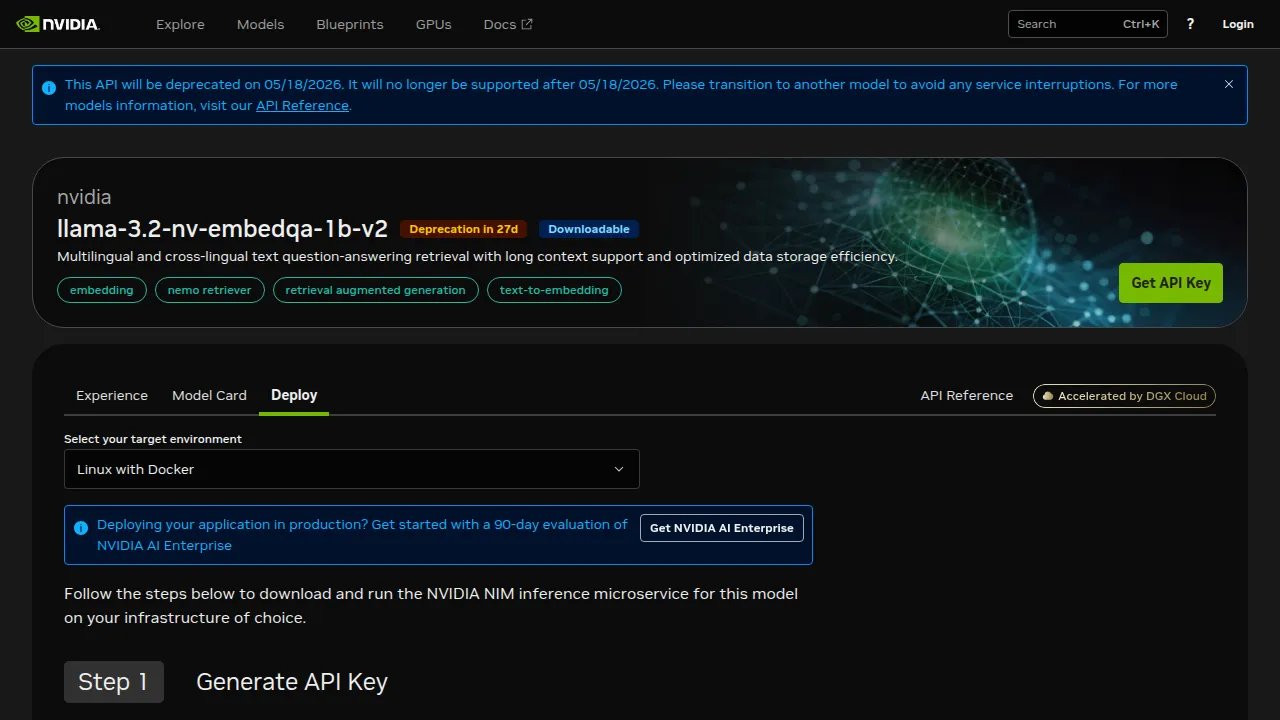
Writing a how-to for a model that loses support in four weeks is how tutorials rot. The orange badge next to the title is the cheapest fact on the page and the most load-bearing.
This is the kind of gotcha that survives on a community forum but rarely makes it into an article: the catalog has two embedding models whose names are almost identical, and the one NVIDIA is actively maintaining is the one without the “3.2-nv-embedqa” suffix — llama-nemotron-embed-1b-v2, labelled as part of the “Nemotron retriever family.” The Model Card makes the case explicitly:
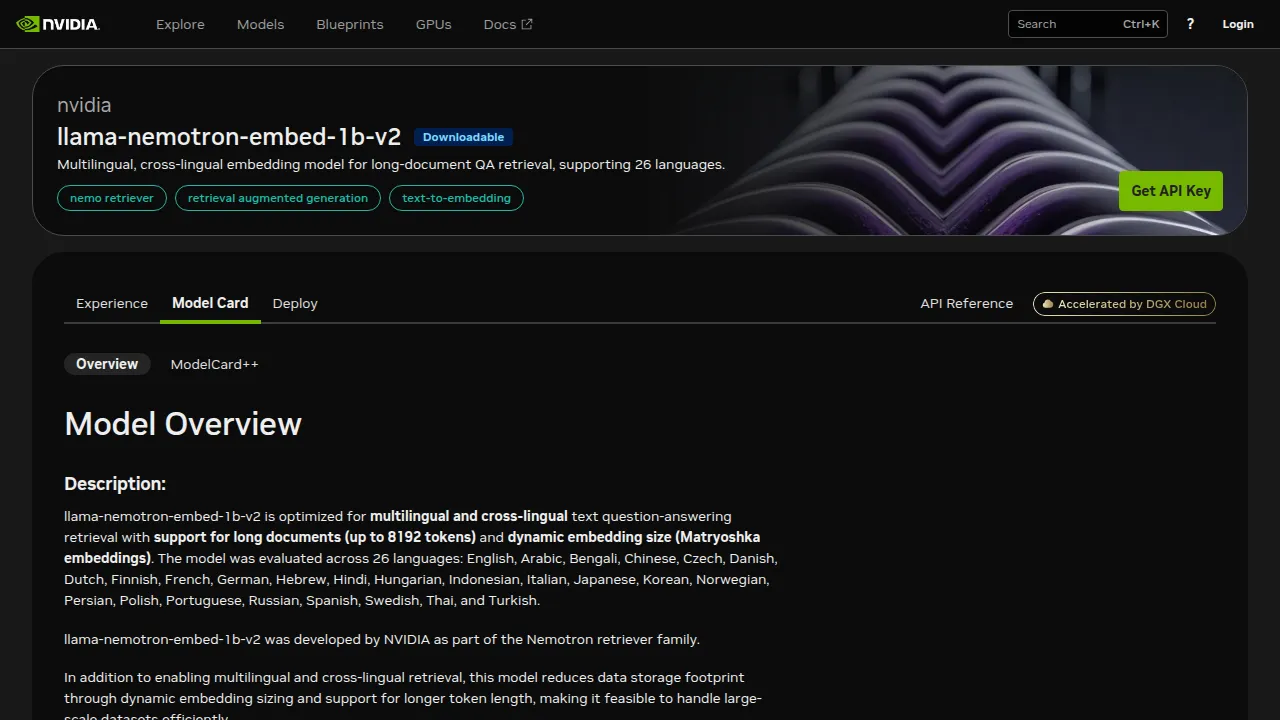
The interesting claim isn’t “multilingual.” It’s Matryoshka — the 2048-dim output works truncated to 384, 512, 768, or 1024 without retraining. That’s a storage-cost slider you don’t usually get for free.
The arm64 manifest check
Before pulling seven gigabytes, the question worth answering in thirty seconds is whether the image even has an arm64 layer. NVIDIA’s catalog pages don’t advertise architectures in the container manifest; you have to ask the registry directly. The Docker Hub-style command works because nvcr.io returns a standard OCI image index:
docker manifest inspect nvcr.io/nim/nvidia/llama-nemotron-embed-1b-v2:latest \
| jq '.manifests[] | .platform'{ "architecture": "arm64", "os": "linux" }
{ "architecture": "amd64", "os": "linux" }Both arches present in the index. Docker’s auto-selector picks arm64 on Spark. This one-liner is the cheapest way to rule out a wasted hour. The handoff from the prior session flagged a community-forum rumor that the older llama-3.2-nv-embedqa-1b-v2 had aarch64 problems — the rumor concerned the deprecated model, and either way the catch has moved on. The current Nemotron embed image ships a clean multi-arch manifest.
First run — 52 seconds cold, one env-var gotcha
With the arch cleared, the launch is one docker run. The command shape matches the one on the Deploy tab, with two Spark-specific changes: I remap to host port 8001 because port 8000 is held by the article-#3 LLM NIM, and I use a per-model cache directory so restarts don’t stomp on the LLM’s cache:
export $(grep -v '^#' ~/.nim/secrets.env | xargs)
mkdir -p ~/.nim/cache/llama-nemotron-embed
docker run -d --restart unless-stopped \
--gpus all --shm-size=16GB \
-e NGC_API_KEY="$NGC_API_KEY" \
-v "$HOME/.nim/cache/llama-nemotron-embed:/opt/nim/.cache" \
-u "$(id -u)" \
-p 8001:8000 \
--name nim-embed-nemotron \
nvcr.io/nim/nvidia/llama-nemotron-embed-1b-v2:latestThe first run of this command gave me back a container and a container log that said, plainly, The requested operation requires an API key, but none was found, followed by a 500 on the readiness probe. The secret was present in ~/.nim/secrets.env; it just wasn’t exported. source ~/.nim/secrets.env sets the shell variable but not the environment variable, so docker run -e NGC_API_KEY inherited an empty string and the container’s internal call to api.ngc.nvidia.com failed before weight download could start. Two fixes work: the export $(grep -v '^# ' ~/.nim/secrets.env | xargs) line above, or -e NGC_API_KEY="$(grep NGC_API_KEY ~/.nim/secrets.env | cut -d= -f2)". Neither is documented on the Deploy tab.
After the re-run, the shape of the startup is cleanly visible in the log:
INFO 2026-04-22 21:28:52 profiles.py:188] Matched profile_id in manifest from env NIM_MODEL_PROFILE:
e28f17c9c13a99055d065f88d725bf93c23b3aab14acd68f16323de1353fc528
INFO 2026-04-22 21:28:52 tokio.rs:916] "nim/nvidia/llama-nemotron-embed-1b-v2:fp16-7af2b653":
fetching filemap from https://api.ngc.nvidia.com/...
...
I0422 21:29:43 metrics.cc:782] "Collecting CPU metrics"
I0422 21:29:43 grpc_server.cc:2562] "Started GRPCInferenceService at 0.0.0.0:8001"
I0422 21:29:43 http_server.cc:4789] "Started HTTPService at 0.0.0.0:8080"
W0422 21:29:44 metrics.cc:643] "Unable to get power limit for GPU 0."Two signals worth naming. First: Triton, not vLLM — the engine under Nemotron Retriever is Triton 2.61 with a GRPC service plus a metrics endpoint. That matters because the observability story later (article #9’s guardrails, whatever observability piece lands after that) plugs into Triton’s metrics endpoint directly rather than scraping vLLM’s OpenAI-compatible server. Second: the FP16 profile, not FP8 — confirmed via the fp16-7af2b653 tag. FP16 is fine for 1B parameters on 128 GB unified memory; you wouldn’t quantize a 1B model unless you were targeting edge-of-edge hardware. The power-metrics warning is GB10’s usual NVML gap; we saw it in article #3 and it will keep showing up every time Triton boots.
From the docker run to the first 200 on /v1/health/ready: 52 seconds, with a 2.4 GB weight download inside that window. The image itself is 7.2 GB compressed; the weights are 2.4 GB (FP16 for a 1.2B-parameter encoder — matches the math). Warm restart is faster still — the cache-volume bind-mount keeps the weights on the host between container lifecycles.
The sanity check — 2048 dimensions and a distance that reads
The first request is the one that tells you everything. curl -X POST http://localhost:8001/v1/embeddings with a single 500-token chunk returns a JSON object whose data[0].embedding is a list of 2048 floats and whose usage.total_tokens — the NIM reports token counts on the embed endpoint, useful for cost modelling even though there’s no per-token cost here — came back as 539 for the corpus chunk I sent. The dimension matches the Model Card; the token count matches what tiktoken-style heuristics predict for a ~2000-character English prose passage. The pipe is wired up.
The second test is the one the vendor’s smoke-test doesn’t do: does the distance metric behave like a distance metric? I embedded a query, a closely-related passage, and a totally unrelated passage about espresso, then ran cosine similarity by hand:
query = "How do unified-memory architectures help large language model inference?"
near = "Grace Blackwell's shared CPU/GPU memory lets LLM weights exceed typical discrete-GPU VRAM limits."
far = "Espresso is brewed by forcing pressurized hot water through finely-ground coffee."| Pair | Cosine similarity |
|---|---|
| query vs near | 0.3466 |
| query vs far | -0.0518 |
The gap is what matters, not the absolute values. A positive cosine around 0.35 for a semantically related passage and a near-zero (slightly negative) cosine for an unrelated one means the model is separating meaning the way retrieval assumes. A vendor’s smoke test proves the endpoint returns bytes. This test proves the endpoint returns useful bytes.
Benchmark — 40 ms single, 28 docs/s plateau
For load shape I sent a representative ~500-token English prose chunk through the endpoint three ways: single-doc sequentially, batch=8 per request, batch=32 per request. Every measurement is the median of 5 to 20 samples after three warmup calls. The Python is boring — urllib.request plus time.perf_counter — so I’ll show the numbers:
| Load | p50 latency | Throughput | Per-token rate |
|---|---|---|---|
| batch=1 | 40 ms / req | 24.8 docs/s | 13,342 tok/s |
| batch=8 | 279 ms / req | 28.7 docs/s | 15,463 tok/s |
| batch=32 | 1118 ms / req | 28.6 docs/s | 15,427 tok/s |
Two observations from that table. First, the batch=1 number is bizarrely familiar — 24.8 docs per second is the same number article #3 measured for Llama 3.1 8B generation throughput in tokens per second, on the same machine. A coincidence, not a relationship: they’re independent subsystems that happen to land on the same digit. Second, the throughput plateau at batch=8 is the interesting curve. Going from batch=8 to batch=32 doesn’t buy you anything — 28.7 docs/s → 28.6 docs/s is inside noise, while the per-request latency quadruples from 279 ms to 1118 ms. The GPU is saturated at batch=8; bigger requests just queue tokens without improving throughput, and they hurt your p99 because the slowest request in a batch sets the wall-clock for all thirty-two.
Verification — what a healthy embed NIM looks like on Spark
nvidia-smi during the batch=32 load confirms the saturation:
utilization.gpu, power.draw [W], temperature.gpu
77 %, 18.65 W, 45
78 %, 33.82 W, 46
74 %, 33.34 W, 46
78 %, 33.62 W, 4774-78% utilization at the Triton-engine side, sustained power draw around 33 W — roughly a third of the Spark’s sustained budget — peak temperature 47 °C. This is the shape of a well-loaded embedder: the GPU is busy but not pegged (there’s still room for the LLM NIM to serve traffic concurrently), and the thermal headroom for a co-resident reranker in the next article is unambiguous.
Host-side, docker stats reports the embed container holding 3.6 GiB resident, the LLM NIM 2.2 GiB, the NemoClaw sandbox 0.5 GiB, total host usage 75 GB of 122 GB. Unified memory means the container’s 3.6 GiB is also the model’s GPU-side footprint; there’s no separate VRAM column to read. The mental model carries over from article #3: on Spark, when a container says it’s using 3.6 GiB, that is the answer, for both CPU and GPU simultaneously.
Tradeoffs, gotchas, surprises
Matryoshka is a storage-cost slider, not a quality free lunch. The 2048-d output is the reference; the truncated dims are useful when the index grows large and you’re willing to pay a few points of retrieval accuracy for a smaller pgvector column. The Model Card’s benchmark tables show the rough shape — at 384 dims the NDCG@10 on the cross-lingual QA benchmark sits around 64%, at 2048 dims it’s 68.6%. About four points of quality for ~5× less storage. That’s a real tradeoff, and it’s the kind of knob you commit to early in a project and regret turning later because it changes the vector-store schema. Decide up front; article #5 (pgvector-on-spark) will have to live with whichever dim you picked here.
The API-key-not-exported trap is unforced and worth a line in NVIDIA’s docs. Every NIM I’ve run so far — the LLM NIM in article #3, this one, presumably the reranker in article #7 — needs NGC_API_KEY in the container environment at launch, not merely docker login. The Deploy tab walks you through docker login and then switches to docker run with an -e NGC_API_KEY flag without flagging that your shell variable has to be exported for that flag to do anything. The first time I hit it I lost a minute; the second time (this article) I saw a familiar error and fixed it in seconds. Both times the fix was out-of-band of the documented flow.
Triton’s power/memory metrics are still N/A on GB10. Same symptom as article #3: nvidia-smi --query-gpu=memory.total,memory.used,power.limit returns [N/A] inside the container, and Triton logs a W … metrics.cc:643] Unable to get power limit for GPU 0. warning on every metrics tick. Unified memory is OS-managed on Grace-Blackwell; NVML’s driver-side query doesn’t have a number to report. It’s cosmetic for now — nvidia-smi --query-gpu=utilization.gpu,power.draw,temperature.gpu all return real values — but any dashboard you wire up to the default NVML attributes will show empty cells on this machine.
The batch-8 plateau shapes the client, not the server. The throughput cap is GPU-bound, not server-bound, so you gain nothing by spamming larger batches from your ingest pipeline. The client wants to pace requests at about 28 per second across as many concurrent clients as your latency SLO allows. A single client hammering batch=32 gets exactly the same docs-per-second as a single client hammering batch=8, with 4× worse p50. That’s a useful fact for the ingest loop in the Wiki arc.
What this unlocks
Three concrete things you can build this week with just this endpoint and article #3’s LLM NIM:
A corpus embedder for your own notes. Walk a directory of markdown or PDF, chunk to ≤ 512 tokens per chunk (the model supports up to 8192 but 512 is the chunk size pgvector indices like), send batches of 8 at the endpoint, persist the vectors to a JSONL file for now. At 28 docs/s, ten thousand chunks finishes in six minutes. That file is the input to article #5 (pgvector-on-spark) when you’re ready to move from a flat file to a queryable store.
A sanity dashboard for retrieval pairs. Cache the embeddings you generate in step one, and build a five-line terminal tool that takes a free-text query and a candidate passage, embeds both, prints the cosine similarity, and colors the output green if > 0.3 and red if < 0.1. Useful before you invest in reranking — it catches systemic retrieval problems (wrong chunk size, wrong input_type flag) that a sophisticated pipeline would hide.
A dedup pass over drafts and notes. For anyone with a messy notes folder: embed every note, find pairs with cosine > 0.85, and review them as dedup candidates. This is the LLM Wiki arc’s second task after “write pages” — dedup is an ingest-time quality check, and on cloud embeddings the per-pair cost punishes you for running it often. Local embeddings don’t punish you at all.
State of the apps
One inference endpoint (article #3) became NIM. One memory layer just became NeMo Retriever embeddings. Second Brain now: has a brain and the start of a memory — just no index yet. LLM Wiki now: has a writer and a dedup signal. Autoresearch now: has a driver and a trajectory-comparison primitive. Next up: pgvector on Spark — the place the vectors live between embed and retrieve.